Uploading datasets to huggingface turned out to be harder than I initially thought.
Data formatting
To be able to view the dataset in the Hugging Face Datasets Hub, the dataset needs to be formatted in the right way. I had an image classification dataset with several target attributes. I followed the guide here. Here is how I formatted the dataset:
./
├── train
│ ├── metadata.csv
│ ├── front_2024_02_29_14_26_45.jpg
│ ├── ...
├── test
│ ├── metadata.csv
│ ├── front_2024_05_30_12_30_02.jpg
│ ├── ...where the metadata.csv file contains the file_name as the first column and several other columns each corresponding to a target attribute. Here is a sample:
file_name,brand,usage,condition,type,category,price,trend,colors,cut,pattern,season,text,pilling,damage,stains,holes,smell,material
front_2022_12_14_08_48_42.jpg,Junkyard,Export,3,Jeans,Ladies,50-100,Denim,['Blue'],['Loose'],None,Spring,,4,,Minor,None,None,100%cotton
front_2023_06_29_08_22_48.jpg,Stacy,Reuse,4,Jeans,Unisex,50-100,None,['Brown'],['Tight'],None,All,,3,,None,None,None,"98% cotton, 2% elastane"When rendered in the dataset viewer in the Hugging Face Datasets Hub, the dataset converts the file_name to an image preview with the title image and retains the other columns. Here is the preview of the dataset:
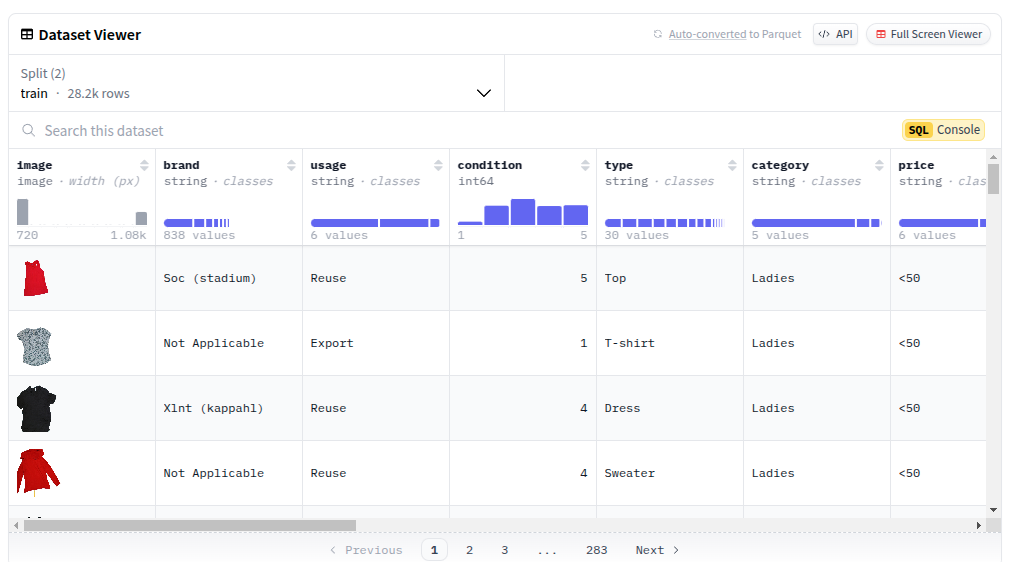
What worked
In the same image_dataset tutorial, they describe how to upload the dataset using the python command:
load_dataset name is misleading: it is not loading the dataset, but it is really setting up your dataset locally in a format suitable for the data viewer in the Hugging Face Datasets Hub. It should really be called setup_dataset.
from datasets import load_dataset
# Load the LOCAL folder as a `huggingface/datasets` dataset
dataset = load_dataset("imagefolder", data_dir="./") # `imagefolder` is a special dataset type that loads images
# Upload the dataset to Hugging Face
dataset.push_to_hub("fnauman/fashion-second-hand-front-only", private=True) # `private=True` makes the dataset repo privateI recommend first uploading the dataset as a private dataset to ensure the upload worked and the data preview works as expected. You can later make the dataset public if you wish.
What did not work
Following the instructions here, I tried using the huggingface-cli command with two variations, but it did not work.
huggingface-cli upload fashion-second-hand-front-only . . --repo-type dataset
huggingface-cli upload-large-folder fashion-second-hand-front-only --repo-type dataset . --num-workers=8Both of these commands crashed and were relatively slow. I suspect it has to do with the large number of files (30,000) in the dataset.